int4 양자화로 인한 VRAM 절감 효과가 크며, 모델별 감소폭은 아래와 같음: 이 수치는 모델 가중치를 로딩하는 데 필요한 VRAM만 포함되며, 실행 중 필요한 KV 캐시는 별도 VRAM을 요구함 QAT 모델은 다양한 플랫폼 및 도구에서 바로 사용 가능:
Gemma 3 소개 및 성능 개요
접근성 향상을 위한 QAT 기반 양자화
QAT를 활용한 품질 유지
VRAM 사용량의 획기적인 감소
다양한 기기에서 실행 가능
손쉬운 통합 및 사용
Gemmaverse의 커뮤니티 모델
지금 바로 시작 가능
Gemma 3 QAT 모델: 최첨단 AI를 소비자 GPU에 도입
 2 weeks ago
11
2 weeks ago
11
Related

AI 부정행위로 아마존 합격한 21세 한인, 75억 투자 받고 데이트까지 속여 논란
7 hours ago
1

Postgres 18을 기다리며: 비동기 I/O로 디스크 읽기 속도 향상
9 hours ago
1
GitHub에서 삭제된 파일을 찾아 버그바운티로 64000달러를 번 스토리
10 hours ago
0

FE News 25년 5월 소식을 전해드립니다!
11 hours ago
0
Gemini 2.0 플래시 프리뷰: 이미지 생성 및 편집 기능 공개
12 hours ago
2
니 적을 알라: 맥킨지 3년이 내 두 번째 스타트업에 준 교훈
12 hours ago
0
유니티의 오픈소스 이중잣대: VLC 차단
13 hours ago
1
Ty - 빠른 Python 타입 체커 및 언어 서버
13 hours ago
1
Popular
Anubis works
3 weeks ago
75
OpenAI, GPT 4.1 공개
3 weeks ago
74
OpenAI, o3 와 o4-mini 모델 공개
3 weeks ago
56
[Vibe Coding 기업 적응기] Part1: v0.dev와 함께한 3주간의 기록
2 weeks ago
53
"100 Go Mistakes and How to Avoid Them"의 뒷이야기
3 weeks ago
48


SAP Business One Pricing & Overview
3 weeks ago
36
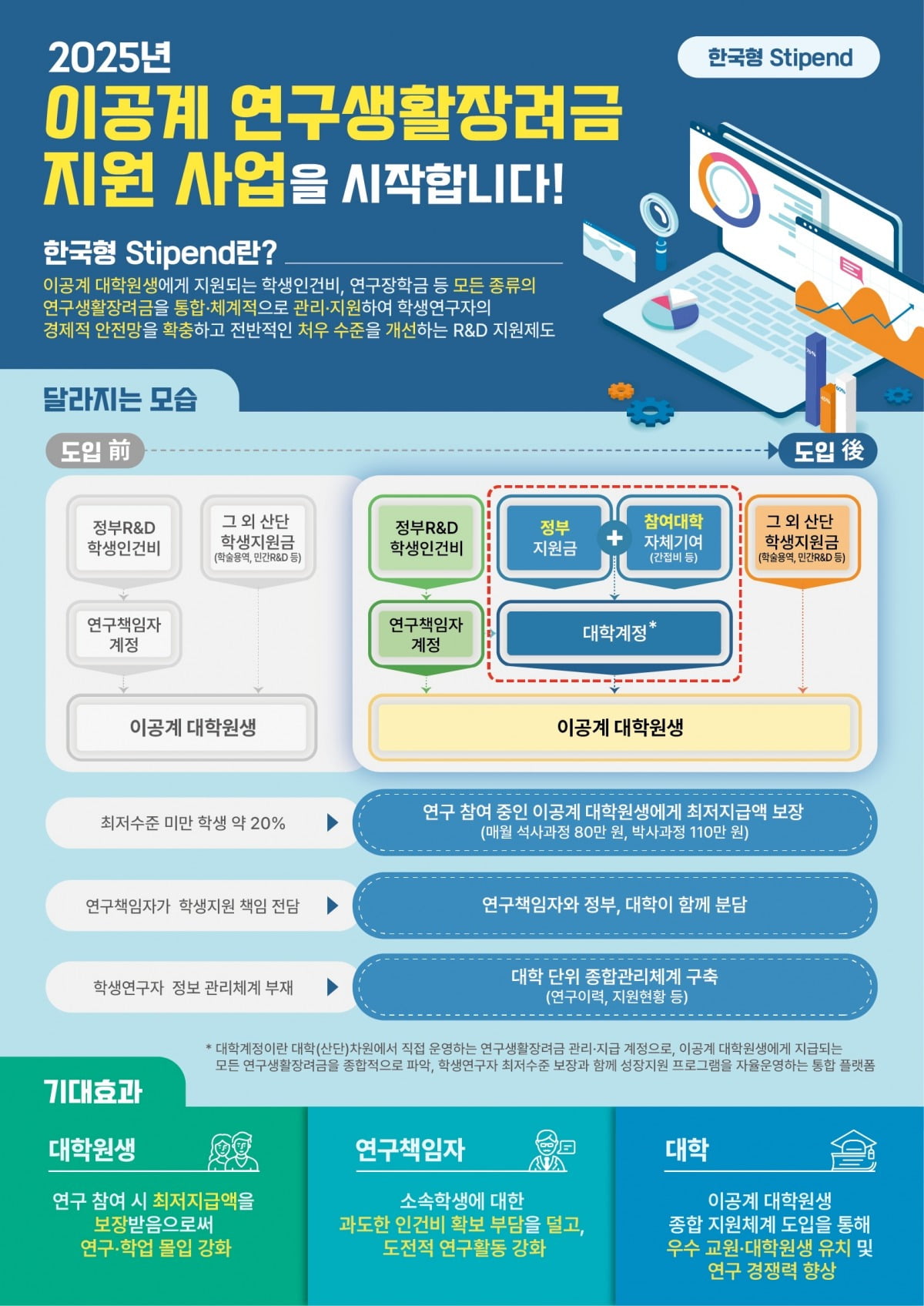
이공계 대학원생, 월 110만원 받는다…'한국형 스타이펜드' 첫걸음
1 week ago
35

 English (US) ·
English (US) · © Clint's Theme Park 2025. All rights are reserved
