실시간 AI 음성 채팅
시스템 작동 방식
주요 기능
기술 스택
사전 요구 사항
설치 및 설정
애플리케이션 실행
설정 세부 사항
기여 및 라이선스
HN 공개: 약 500ms 지연 시간의 실시간 AI 음성 채팅
 1 day ago
4
1 day ago
4
Related

인도, 파키스탄 및 파키스탄령 잠무 카슈미르 내 9개 지역 공격
12 hours ago
0
Claude의 시스템 프롬프트, 도구 포함 24k 토큰 초과
13 hours ago
1
작은 청크 RAG 검색의 정확도를 높이는 Contextual BM25F 전략
14 hours ago
1
누가 휴머노이드를 만드는가?
15 hours ago
0
Show GN: 카보스 - 복잡한 연동 없는 AI 기반 미팅 자동 기록·검색·요약 도구
19 hours ago
0
C++를 통해 Rust의 매력을 보여준 Matt Godbolt의 설득
21 hours ago
1
Cursor 1년간 학생 무료
22 hours ago
1

Popular
Anubis works
3 weeks ago
75
OpenAI, GPT 4.1 공개
3 weeks ago
74
OpenAI, o3 와 o4-mini 모델 공개
3 weeks ago
56
[Vibe Coding 기업 적응기] Part1: v0.dev와 함께한 3주간의 기록
2 weeks ago
53
"100 Go Mistakes and How to Avoid Them"의 뒷이야기
3 weeks ago
48

How to Create Your First SAPUI5 Application
4 weeks ago
41


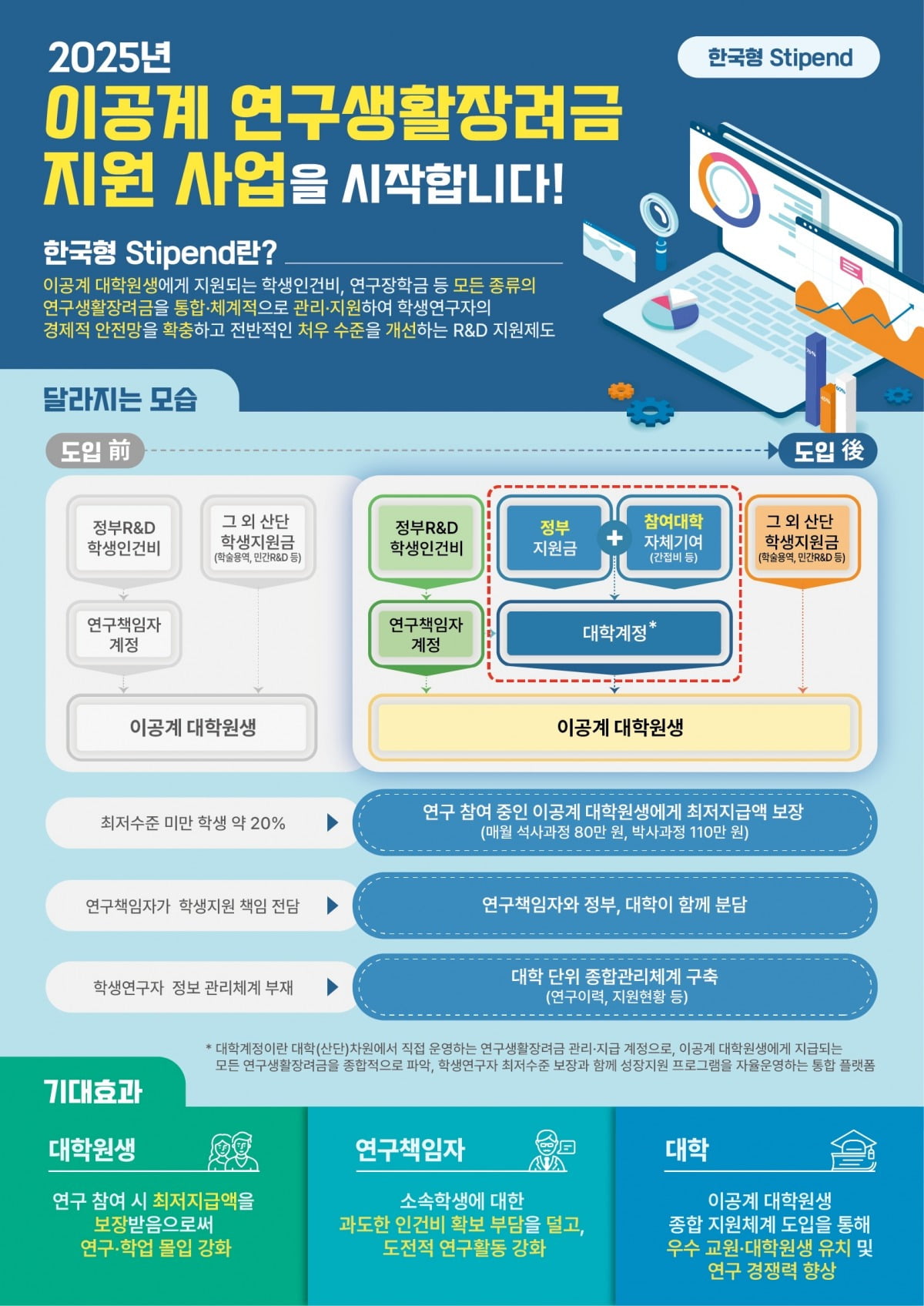
이공계 대학원생, 월 110만원 받는다…'한국형 스타이펜드' 첫걸음
1 week ago
35

SAP Business One Pricing & Overview
2 weeks ago
34
 English (US) ·
English (US) · © Clint's Theme Park 2025. All rights are reserved
