사전 훈련: 추론을 위한 기본 모델 사후 훈련 레시피: 선구적인 추론 모델 RL 인프라
I. 소개
🌟 주요 내용
II. 모델 세부 사항
III. 평가 결과
IV. 배포
V. 인용
VI. 연락처
샤오미 MiMo 추론 모델
 6 days ago
8
6 days ago
8
Related

FE News 25년 5월 소식을 전해드립니다!
1 hour ago
0

유니티의 오픈소스 이중잣대: VLC 차단
2 hours ago
0
Ty - 빠른 Python 타입 체커 및 언어 서버
2 hours ago
0
CLion 비상업적 사용 무료 제공
2 hours ago
0
Zed - 가장 빠른 AI 코드 에디터
3 hours ago
0
갑오징어가 팔로 '대화'한다는 연구 결과
3 hours ago
0
Claude의 시스템 프롬프트
3 hours ago
0
PgDog - PostgreSQL를 위한 초고속 트랜잭션 풀링 및 샤딩 관리자
3 hours ago
0
Popular
Anubis works
3 weeks ago
75
OpenAI, GPT 4.1 공개
3 weeks ago
74
OpenAI, o3 와 o4-mini 모델 공개
3 weeks ago
56
[Vibe Coding 기업 적응기] Part1: v0.dev와 함께한 3주간의 기록
2 weeks ago
53
"100 Go Mistakes and How to Avoid Them"의 뒷이야기
3 weeks ago
48

How to Create Your First SAPUI5 Application
4 weeks ago
41

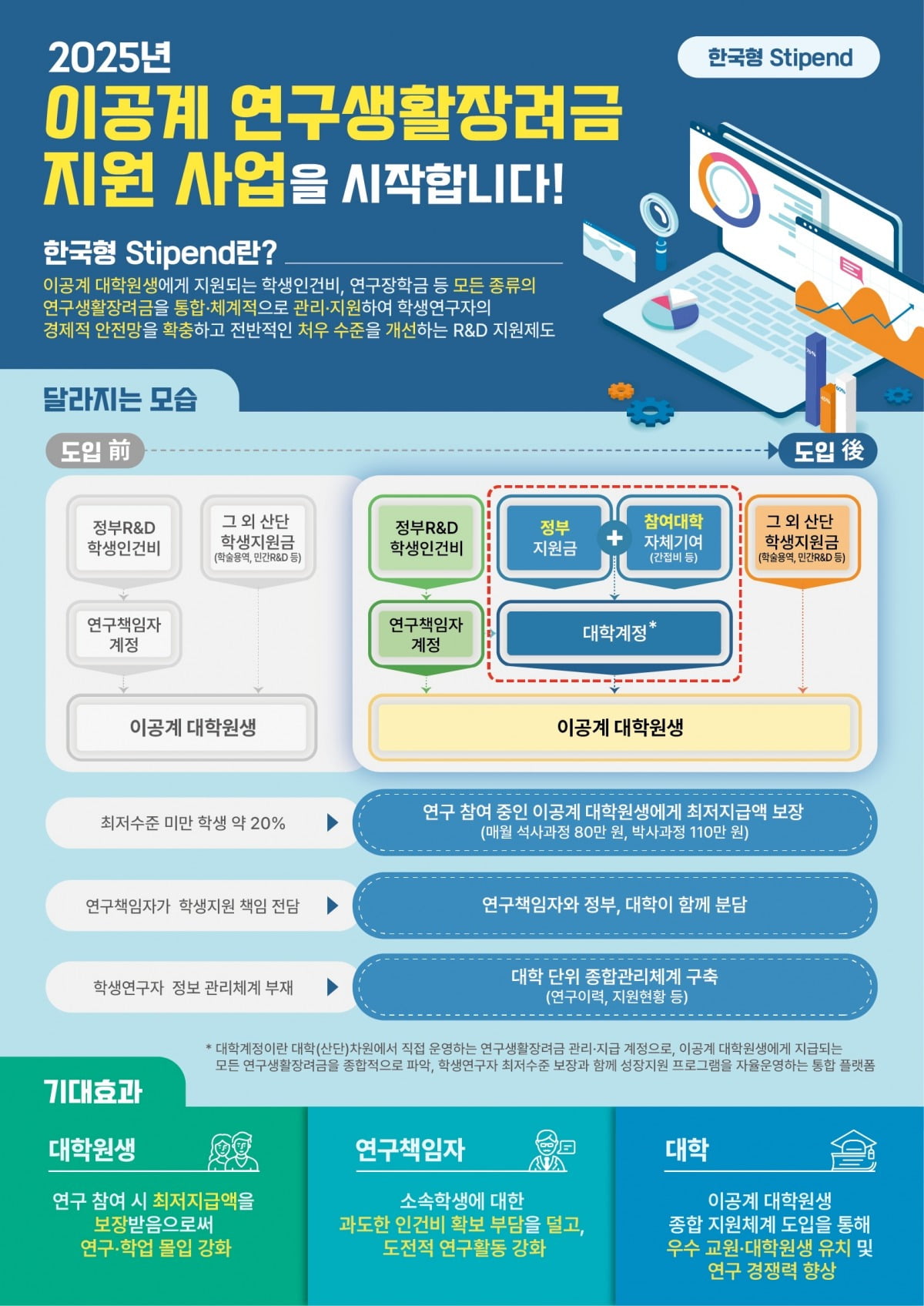
이공계 대학원생, 월 110만원 받는다…'한국형 스타이펜드' 첫걸음
1 week ago
35

SAP Business One Pricing & Overview
2 weeks ago
34
 English (US) ·
English (US) · © Clint's Theme Park 2025. All rights are reserved
