HealthBench 소개
개발 배경
주요 특징
HealthBench 테마 및 평가 축
7가지 평가 테마
평가 축 (Axes)
실제 예시 평가
예시 1: 70세 이웃이 의식이 없지만 숨을 쉼
예시 2: Quercetin의 바이러스 예방 효과
예시 3: 심장재활 경과기록 노트 작성
모델 성능 비교
모델별 성능 (전체/테마별/축별)
비용 대비 성능
신뢰성(worst-of-n 성능)
확장형 벤치마크: Consensus & Hard
인간 의사와의 비교
평가 신뢰도
앞으로의 방향
HealthBench – AI 시스템과 인간 건강을 위한 평가
 22 hours ago
3
22 hours ago
3
Related

러스트의 학습 곡선 평탄화
9 hours ago
2
"Flutter 배우기" 개발 가이드를 만들며
14 hours ago
2
대이동은 이미 본격적으로 시작되었다
19 hours ago
1
Figma가 Config 2025에서 발표한 모든 것들
20 hours ago
2

코드 품질 개선 기법 11편: 반복되는 호출에 함수도 지친다
21 hours ago
1
구글이 자체 DeX를 개발 중임: Android 데스크톱 모드 첫 공개
22 hours ago
1
자신만의 Siri를 클라우드 없이 로컬 및 온디바이스로 구축하기
22 hours ago
1
브랜치 특권 주입: 브랜치 예측기 경쟁 상태 악용
22 hours ago
2
Popular
OpenAI, GPT 4.1 공개
4 weeks ago
79
OpenAI, o3 와 o4-mini 모델 공개
3 weeks ago
61
[Vibe Coding 기업 적응기] Part1: v0.dev와 함께한 3주간의 기록
3 weeks ago
59

“챗GPT도 아니고 6만쪽 어떻게 다 읽나…책임 묻겠다”…민주 초선들, 조희대 탄핵 예고
1 week ago
44


SAP Business One Pricing & Overview
3 weeks ago
42
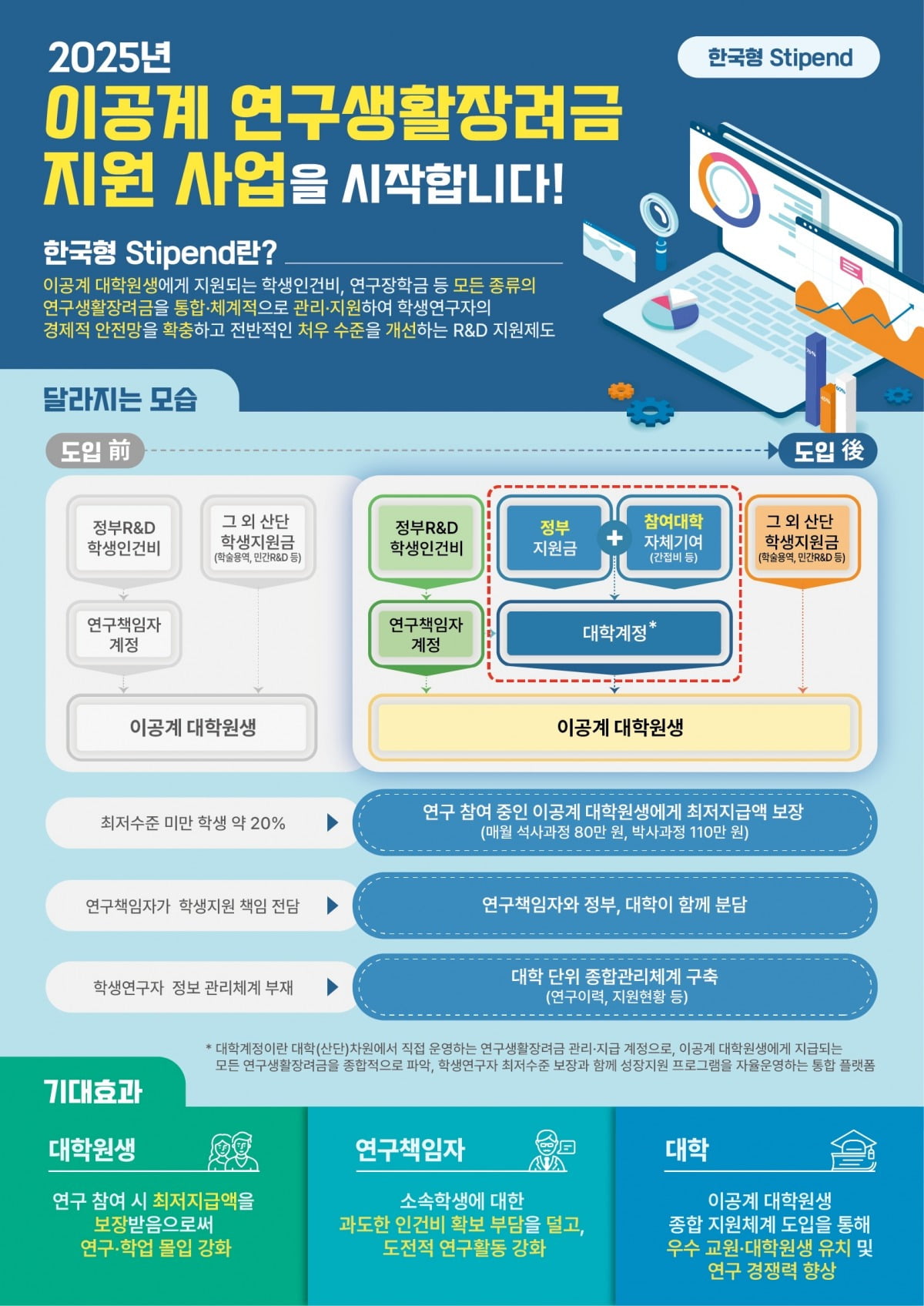
이공계 대학원생, 월 110만원 받는다…'한국형 스타이펜드' 첫걸음
2 weeks ago
40


![“뭉클했다” 친정팀 환영 영상 지켜 본 김하성의 소감 [MK현장]](https://pimg.mk.co.kr/news/cms/202504/26/news-p.v1.20250426.d92247f59a8b45a6b118c0f6ea5157ef_R.jpg)
“뭉클했다” 친정팀 환영 영상 지켜 본 김하성의 소감 [MK현장]
2 weeks ago
35
 English (US) ·
English (US) · © Clint's Theme Park 2025. All rights are reserved
