OpenAI의 PostgreSQL 대규모 확장 사례
배경
주요 과제
대응 방안
Primary 데이터베이스 부하 분산
쿼리 최적화
단일 장애점(SPOF) 대응
스키마 관리
운영 결과
장애 사례
PostgreSQL에 제안된 기능 개선 요청
Lao Feng의 코멘트
Lao Feng Q&A
인덱스 비활성화 기능
관측성 확장: P95/P99 latency
스키마 변경 이력
모니터링 뷰 의미
기본 파라미터
자체 운영(셀프 호스팅) 옵션
OpenAI: PostgreSQL를 다음 단계로 확장하기
 6 hours ago
2
6 hours ago
2
Related

Linux/Android 성능분석 솔루션 - Guider 3.9.9 릴리즈!
6 hours ago
1
내가 직접 만든 오디오 플레이어
6 hours ago
1
지구에는 서로 반대쪽에 두 개의 만조 융기(High-tide bulges)가 존재하는가?
6 hours ago
1
당신의 사람들을 찾으세요
6 hours ago
0
게임을 넘어 현실까지 배우는 AI: 존 카맥의 현실 기반 강화학습 도전
6 hours ago
1
Microsoft, VS Code용 PostgreSQL IDE 확장의 공개 프리뷰 발표
7 hours ago
1
Crosspost - 여러 SNS에 동시에 게시하는 오픈소스 도구
7 hours ago
0
Guider 3.9.9 릴리즈 – 10주년을 맞이한 가장 큰 업데이트!
7 hours ago
2
Popular

김문수, 배현진에 “미스 가락시장” 발언 놓고 논란
1 week ago
83
Gmail to SQLite
1 week ago
72
21 GB/s 속도의 AMD 9950X에서 SIMD를 활용한 CSV 파싱
1 week ago
68

“챗GPT도 아니고 6만쪽 어떻게 다 읽나…책임 묻겠다”…민주 초선들, 조희대 탄핵 예고
2 weeks ago
48
![“뭉클했다” 친정팀 환영 영상 지켜 본 김하성의 소감 [MK현장]](https://pimg.mk.co.kr/news/cms/202504/26/news-p.v1.20250426.d92247f59a8b45a6b118c0f6ea5157ef_R.jpg)
“뭉클했다” 친정팀 환영 영상 지켜 본 김하성의 소감 [MK현장]
4 weeks ago
46
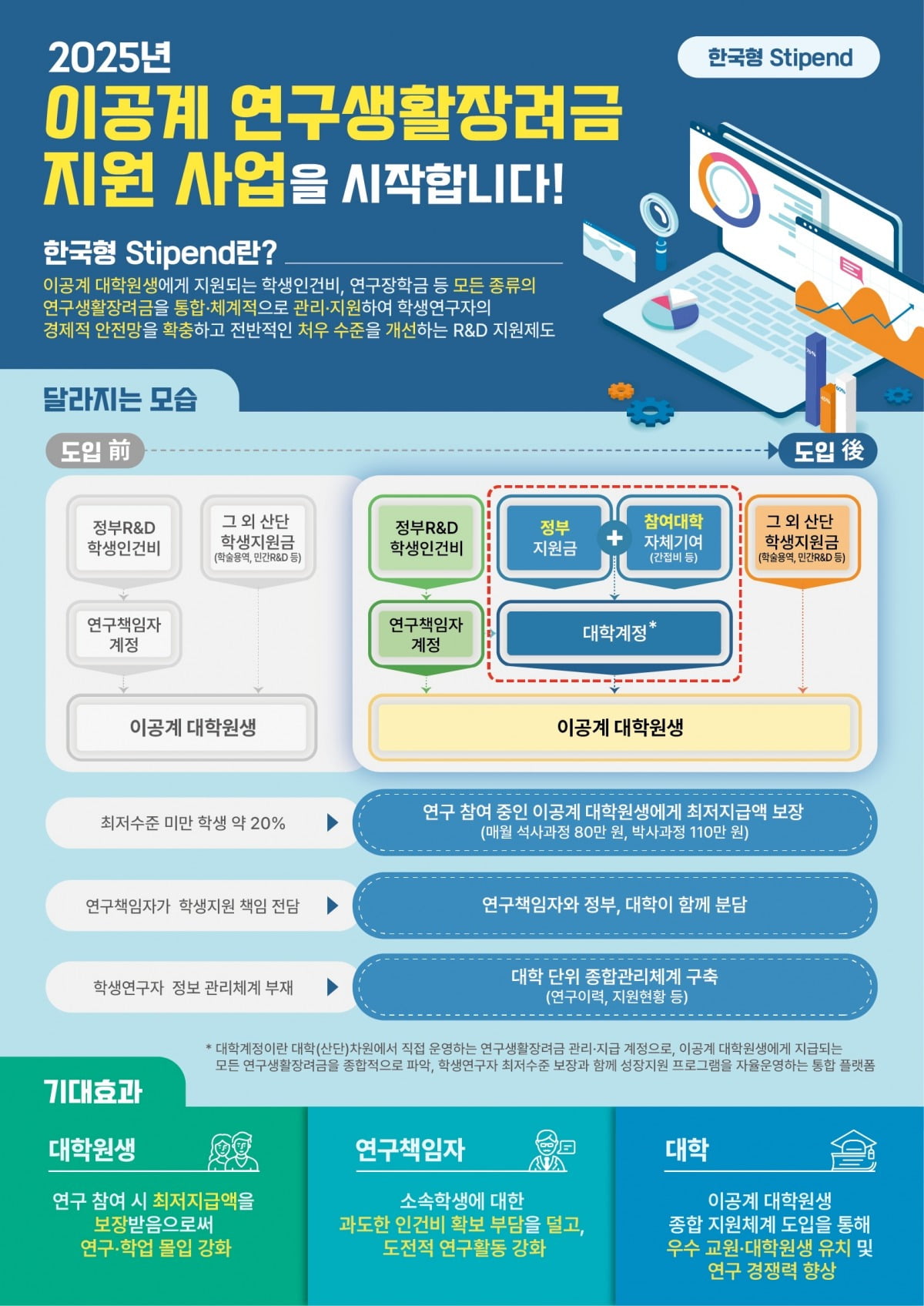
이공계 대학원생, 월 110만원 받는다…'한국형 스타이펜드' 첫걸음
4 weeks ago
46
Cloth 웹 시뮬레이터
3 weeks ago
43


Maintaining Security Material with SAP Cloud Integration
3 weeks ago
33

교황 선출 비밀투표를 OTT로…판돈 260억 몰린 '콘클라베' 생중계
2 weeks ago
31
 English (US) ·
English (US) · © Clint's Theme Park 2025. All rights are reserved
