TL;DR
네트워크 호출 없이 모바일 기기 내부에서 작동하는 이미지 이해 기능을 개발했습니다. 그 과정에서 거대 모델(teacher)의 정교한 표현력을 작은 모델(student)에게 전수하여 성능은 유지하면서 크기와 연산량을 획기적으로 줄이는 '지식 증류(knowledge distillation)' 기법을 핵심 전략으로 활용했습니다.
구체적으로는 이미지-텍스트 임베딩 모델을 활용해 영어 전용 텍스트 인코더를 지식 증류를 활용해 다국어(영어/일본어/중국어(번체)/태국어/한국어)로 확장했고, 의미 기반 이미지 검색을 테스트해 보았습니다.
- 핵심 성과: 다국어를 지원하는 이미지 검색 기능 구현(지식 증류 기법을 활용해 5개 언어 Recall@5 평균 78% 달성)
들어가며: 왜 ‘메신저용’이고 왜 ‘온디바이스’인가
메신저 시나리오에서 이미지 이해가 필요한 이유
메신저에는 텍스트만큼이나 사진과 이미지가 많이 오갑니다. 텍스트 메시지는 검색이나 요약, 알림 미리보기 기능을 구현하기가 비교적 쉽지만, 이미지 메시지는 ‘사진’이라는 한 가지 타입으로만 취급되는 경우가 많기 때문에 그렇지 않습니다. 이 간극이 사용자 경험(UX) 저하로 이어졌습니다. 예를 들어 알림 화면에서 "사진 1개를 보냈습니다" 대신 "강아지 사진을 보냈습니다"처럼 내용을 한 번 더 해석해 주는 문장이 나온다면 사용자는 앱을 열기 전에도 맥락을 더 잘 파악할 수 있을 것입니다.
검색도 비슷합니다. 키워드 기반 검색은 텍스트에는 강하지만 이미지에는 적용하기 어렵습니다. 반면 이미지와 텍스트를 같은 임베딩 공간(embedding space)에 놓으면 '강아지 / 멍멍이 / 개'처럼 표현이 달라도 같은 의미를 찾아낼 수 있고 '박스 안의 고양이'처럼 복잡한 의미도 표현할 수 있으며, 언어가 달라도 같은 결과로 이어질 수 있습니다.
결과적으로 이미지 이해는 알림·검색·추천 같은 메신저의 여러 접점에서 기본 기능을 한 단계 끌어올리는 기반이 될 수 있습니다. 이에 여러 메신저 기능 개선에 도움이 되었으면 하는 바람으로 메신저용 온디바이스 이미지 모델을 만들었습니다.
예제 사용자 시나리오
- 알림 개선: "사진 1개를 보냈습니다" → "강아지 사진을 보냈습니다"
- 검색 확대: "강아지", "멍멍이", "개" 혹은 "박스 안에 고양이"와 같은 자연어로 의미 기반 검색 제공
- 추천 개선: 이미지 자동 분류 및 추천
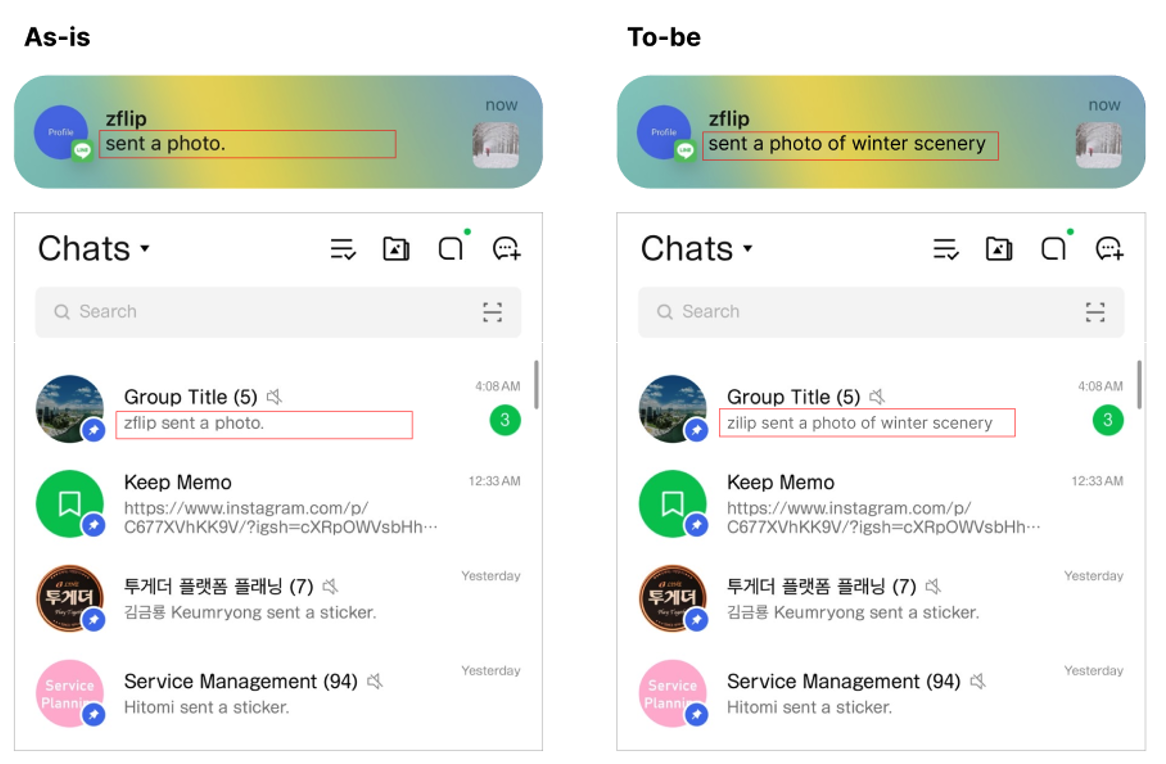 알림 개선 예제 이미지
알림 개선 예제 이미지
서버가 아닌 온디바이스에서 풀어야 했던 이유
이미지 이해는 서버에서 처리하는 것이 가장 흔한 형태지만, 메신저 환경에서는 '온디바이스'가 사실상 전제 조건에 가까웠습니다. 그 이유는 다음과 같습니다.
- 지연(latency): 모바일 환경은 체감 지연에 매우 민감합니다. 네트워크 왕복 시간(round trip time, RTT)에 따라 결과가 흔들리면 사용자 경험이 쉽게 나빠집니다. 특히 알림과 검색 같은 예제 시나리오에서 매우 중요한 요소입니다.
- 프라이버시: 개인 사진 또는 그로부터 생성된 임베딩이나 캡션이 서버로 전송되는 순간 프라이버시와 관련해 기능의 민감도가 크게 올라갑니다.
- 오프라인 혹은 불안정한 네트워크 환경: 지하철이나 비행기 안 또는 로밍한 상황 등에서도 잘 작동해야 했습니다.
- 모델 크기 및 호환성: Android/iOS 모두에서 제한된 메모리와 연산 자원으로 안정적으로 작동해야 했고, 다운로드 부담도 고려해야 했습니다.
‘메신저용 온디바이스 이미지 모델 학습기’ 시리즈에서 다룰 내용
두 편으로 구성한 이 시리즈에서는 약 6개월간 진행한 온디바이스 PoC(proof of concept) 프로젝트 중 두 가지 핵심 기술을 중점적으로 다룰 예정입니다.
- 이미지 벡터 검색: 텍스트 이미지 간 임베딩 기반 의미 검색 및 로컬 벡터 DB 인덱싱 도입(비디오 벡터 검색은 이미지 벡터 검색의 확장 사례로 간략히 언급)
- 이미지 캡션 생성(captioning): 짧은 캡션을 초저지연으로 생성하는 비자기회귀(non-autoregressive, non-AR) 전략 도입
한 편에 모두 담기에는 분량이 다소 많아 두 편으로 나눴습니다.
1편에서는 메신저 환경에서 온디바이스로 이미지 이해를 구현해야 했던 배경과 제약을 정리한 뒤, 지식 증류로 텍스트 인코더를 다국어로 확장해 온디바이스 이미지 검색을 가능하게 만든 과정을 다룹니다.
2편에서는 이미지 캡션 생성 시 가장 큰 병목이었던 자기회귀(AR) 디코딩 지연을 비자기회귀 전략으로 바꿔 200~400ms급 초저지연을 달성한 다단계 지식 증류 학습 방법을 소개하겠습니다.
문제 정의 및 목표 지표 설정
목표 1: 텍스트와 이미지 간 의미 유사도에 기반한 다국어 지원 이미지 검색 기능 구현
검색은 '이미지와 텍스트를 같은 임베딩 공간으로 사상한 뒤 코사인 유사도(cosine similarity)로 가까운 것을 찾는다'라는 아이디어로 정리됩니다. 이때 영어뿐 아니라 '강아지 / 犬 / ลูกสุนัข'처럼 다국어 쿼리가 같은 이미지를 가리키게 만드는 것이 핵심입니다.
목표 1의 요구 사항을 정리하면 다음과 같습니다.
- 의미 기반 검색: 키워드 매칭이 아닌 의미적 유사성(semantic similarity)
- 다국어(영어, 일본어, 중국어(번체), 태국어, 한국어) 지원
목표 2: 빠른 속도로, 짧게 잘 정리된 자연스러운 캡션 생성
LINE 앱과 같은 메신저 환경에서 중요한 건 장문의 상세한 설명이 아니라, 짧고 일반적인 표현으로 '무슨 사진인지'를 전달하는 것입니다. 이를 위해 길이는 대략 8 단어 정도로 제한했습니다. 이때 문장은 문법 오류가 없으면서 불필요하게 반복되는 단어나 오타도 없어야 했습니다. 예를 들어 "a desk with a computer on a desk"처럼 ‘a’가 불필요하게 반복되는 문장은 사용자가 즉시 이상하다고 느낄 수 있습니다. 따라서 "a desk with a computer"처럼 짧게 정리된 문장을 빠르게 생성하는 것이 목표였습니다.
목표 2의 요구 사항을 정리하면 다음과 같습니다.
- 모바일 UX를 만족할 빠른 속도
- 짧고(8 단어 이하), 문법 오류/불필요한 반복/오타 등이 없는 자연스러운 문장 생성
목표 2를 어떻게 달성했는지는 2편에서 말씀드릴 예정입니다.
공통 목표: 온디바이스 배포
두 기능 모두 실서비스에 배포 가능한 수준이 목표였기 때문에 모델 크기·속도·호환성을 동시에 만족해야 했습니다. 모델 크기는 앱 다운로드 부담을 고려해 200 MB 이하를 목표로 설정했고, 콜드 스타트(cold start)를 포함해 수백 ms 이내의 응답을 지향했습니다. 런타임은 Android/iOS 모두를 지원하는 LiteRT를 기준으로 설계했습니다.
공통 목표 요구 사항
- 모델 크기를 줄여 앱 다운로드 부담 최소화(목표 <200MB)
- 콜드 스타트 포함 수백 ms 이내의 속도
- 호환성: Android/iOS 지원
평가 지표
검색은 전통적으로 쓰이는 Recall@K를 사용했습니다. 이미지에서 텍스트(Image-to-Text) 방향과 텍스트에서 이미지(Text-to-Image) 방향 모두를 측정했고, 주로 Recall@5를 사용했습니다.
캡션 품질은 CIDEr, CLIPScore 같은 지표를 참고하되, 모바일 UX에서 더 중요한 '실제 서비스 사용 가능 여부'를 포착하기 위해 LLM 기반 수락 비율(accept ratio)을 지표로 추가했습니다. 반복·오타·문법 오류 등으로 '실제 서비스서 사용하기 어렵다'라고 판단되는 케이스를 직접 잡기 위한 선택이었습니다.
- 검색 지표
- Image-to-Text Recall@5
- Text-to-Image Recall@5
- 캡션 지표
- CIDEr(전통적 캡션 평가 지표)
- CLIPScore(의미적 유사도)
- 수락 비율(실사용 품질, GPT-4o mini 기반)
다국어를 지원하기 위한 지식 증류: 온디바이스 이미지 검색
 온디바이스 이미지 검색의 대표적인 흐름
온디바이스 이미지 검색의 대표적인 흐름
다국어 지원을 어떻게 해결할 것인가
기존 방식: 번역 파이프라인
처음에는 사용자 질의를 영어로 번역한 다음, 영어 전용 텍스트-이미지 임베딩 모델을 사용하는 방식이었습니다.
사용자 질의 → 언어 판별 → 번역 → 텍스트-이미지 임베딩 모델 (영어 only) → 임베딩 → 검색구현은 빠르지만 메신저에서 '검색'되기 위해 이 파이프라인이 요구하는 것이 생각보다 많았습니다. 번역 품질이 흔들리는 순간 검색 결과가 흔들렸고, 번역 때문에 늘 지연 시간이 늘어났습니다.
왜 번역 파이프라인만으로는 부족했나
번역 기반 접근은 네 가지 이유로 한계를 드러냈습니다.
첫째, 품질입니다. 짧은 키워드나 구어체에서 의미가 손실되는 경우가 잦았습니다. 예를 들어 저희가 찾고 싶은 건 ‘소리’가 아니라 ‘개(dog)’였는데 "멍멍이"가 "barking"으로 번역돼 버리면 검색이 엇나갑니다. 더불어 고유명사나 신조어도 종종 불안했습니다.
둘째, 지연입니다. 번역(예: 50ms)이 한 번 들어가면 텍스트 인코딩(예: 100ms) 앞에 고정 비용이 붙습니다. 특히 모바일 UX처럼 바로 반응해야 할 때 이 비용은 크게 체감됩니다.
셋째, 일관성입니다. 언어 쌍마다 번역 품질 편차가 있고, 동일 의미라도 번역 경로에 따라 결과가 달라질 수 있습니다. 이는 검색 결과의 예측 가능성을 떨어뜨렸습니다.
넷째, 운영 부담입니다. 언어가 늘어날수록 번역 모델의 다운로드/업데이트/실패 처리까지 관리 포인트가 늘어납니다. 이 때문에 ‘기능을 하나 더 붙였더니 운영이 하나 더 생기는 형태’가 되기 쉽습니다.
선택지 비교: 다국어 모델을 직접 만들기 vs 지식 증류로 확장하기
다국어 문제를 풀기 위한 선택지는 크게 두 가지였습니다. 하나는 다국어 지원 이미지-텍스트 임베딩 모델을 처음부터 학습하는 것이고, 다른 하나는 이미 검증된 영어 임베딩 공간에 다국어를 정렬하는 것입니다. 전자는 데이터와 연산 비용이 너무 컸고, 후자는 기존 이미지 인코더를 재활용할 수 있어 효율적이었습니다.
이에 저희는 지식 증류로 다국어 텍스트 인코더를 만든다는 방향을 택했습니다. 당시에 지원하는 언어를 영어로만 한정한다면 우수한 성능과 효율적인 용량을 가진 이미지-텍스트 임베딩 모델이 이미 다수 존재했습니다. 따라서 '이미 잘 동작하는 영어 임베딩 공간은 유지하고, 텍스트 쪽만 다국어로 늘린다'는 전략이 유효할 것이라고 판단했습니다.
핵심 아이디어 1: 지식 증류를 활용해 다국어 텍스트 인코더 만들기
교사(teacher) 모델-학생(student) 모델 임베딩 정렬
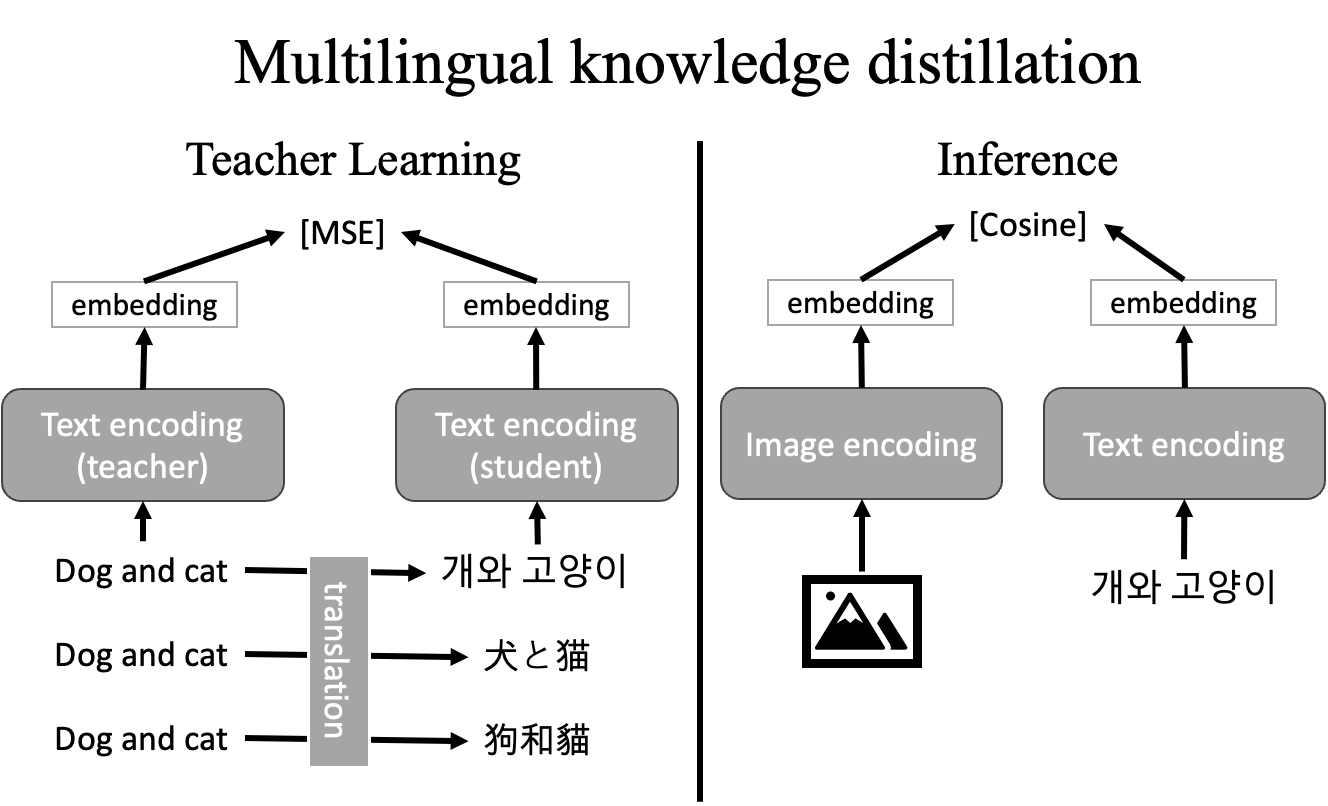 다국어 지식 증류 방법
다국어 지식 증류 방법
지식 증류의 핵심은 교사 모델의 출력을 학생 모델이 따라가도록 만드는 것입니다. 이 프로젝트에서는 원본 텍스트 인코더(영어)를 학습되지 않도록 고정(frozen)하여 교사로 삼았습니다. 학생 모델은 동일한 구조를 복제한 뒤 다국어 입력을 받아 같은 임베딩을 내도록 학습합니다. 두 임베딩 사이의 거리는 MSE(mean squared error, 평균 제곱 오차)로 최소화했습니다. 정리하면 다음과 같습니다.
- 교사 모델: 원본 텍스트 인코더 (영어, 고정)
- 학생 모델: 복제한 텍스트 인코더 (다국어, 학습 대상)
- 손실(loss): MSE(교사와 학생의 임베딩 비교)
학습 자체는 간단하지만 '어디까지 건드릴 것인가'가 중요했습니다. 저희는 이미지 인코더를 재학습하지 않고 고정(freeze)했습니다. 이미 이미지 인코더의 품질이 충분했고, 임베딩 공간을 흔들고 싶지 않았기 때문입니다. 대신 텍스트 인코더만 분리·복제해 교사/학생을 구성했고, 교사 모델은 고정한 채 학생 모델만 업데이트했습니다. 이 아이디어는 Radford et al., "Learning Transferable Visual Models From Natural Language Supervision", ICML 2021과 Wang et al., "Cross-lingual and Multilingual CLIP", LREC 2022 논문을 참고했습니다.
학습 과정:
# 의사코드 teacher_model.eval() # teacher는 frozen for batch in dataloader: en_text, multilang_text = batch with torch.no_grad(): teacher_emb = teacher_model(en_text) # 영어 임베딩 student_emb = student_model(multilang_text) # 다국어 임베딩 loss = F.mse_loss(teacher_emb, student_emb) loss.backward() optimizer.step()이렇게 학습하면 학생 모델은 영어 교사 모델이 만들어 둔 임베딩 공간을 '그대로' 사용합니다. 결과적으로 이미지 인코더(영어 기준으로 학습된 것)는 그대로 두고, 텍스트만 다국어로 입력할 수 있게 됩니다.
학습 시 팁으로는 토큰화기(tokenizer)가 다국어 문자를 안전하게 처리하는지, 대소문자 처리(case-insensitive) 정책을 어떻게 둘지, 언어별 데이터 불균형이 생기지 않도록 어떻게 샘플링할지와 같은 주변 요소를 세심히 살펴야 했습니다. 특히 모바일에서 추론까지 염두에 두면 모바일에서의 토큰화기 구현과 전처리 일치가 성능에 직접 영향을 주기 때문에, 학습 단계에서부터 미리 규약을 정해 두는 것이 중요했습니다.
다국어 텍스트 인코더 성능 측정 결과
다음은 각 언어별 Recall@5를 측정 결과입니다.
| 영어만 | 79.58 | 11.14 | 10.92 | 2.83 | 1.25 |
| 다국어(multilingual) | 76.56 | 81.94 | 76.86 | 80.39 | 79.25 |
| 영어만 | 75.89 | 5.03 | 1.89 | 1.58 | 0.25 |
| 다국어 | 74.47 | 80.44 | 75.47 | 78.28 | 78.22 |
측정 결과 영어 성능은 이미지 -> 텍스트 기준으로 79.58→76.56(약 3%p), 텍스트 -> 이미지 변환 기준으로 75.89→74.47(약 1.4%p)로 소폭 성능이 하락했지만 허용 가능한 수준이었습니다. 반면 다국어 성능은 평균 10% 미만에서 평균 78% 이상으로 약 7배 향상되면서 '거의 검색이 불가능한 수준'에서 '실제로 사용할 수 있는 수준'으로 올라왔습니다. 특히 일본어는 81.94%로 영어 원본보다도 높은 성능을 보였고, 중국어(번체), 태국어, 한국어 모두 실제 사용 가능한 수준에 도달했습니다.
결과적으로 영어 성능을 약간 희생하는 대신 4개 언어를 획득했으며, 이 트레이드오프 덕분에 전체적으로는 훨씬 더 큰 가치를 제공할 수 있게 되었습니다.
온디바이스 구현 1: PyTorch에서 LiteRT로 변환
LiteRT를 선택한 이유
LiteRT를 선택한 이유는 간단합니다. Android와 iOS 모두 공식적으로 지원하는 표준 런타임이기 때문입니다. 또한 모바일에 최적화된 연산자를 제공하고, 양자화 및 최적화 도구가 풍부했습니다. 그에 반해 CoreML은 iOS에서만 작동하며, 모델 변환 시 호환성 문제도 발견됐습니다. 또한 향후 크로스 플랫폼 유지 보수 부담도 컸기 때문에 제외했습니다.
변환 과정에서 해결한 과제
연산(operator) 호환 문제
LiteRT로 모델을 변환할 때 발생할 수 있는 가장 큰 문제는 LiteRT가 모든 PyTorch 연산을 지원하지 않는다는 점입니다. 예를 들어 에러 함수(error function)인 erf를 LiteRT에서는 지원하지 않기 때문에 모델 내부의 연산를 의사-efr(pseudo-erf)로 변경해서 구현해야 합니다.
주요 문제 사례:
- erf(에러 함수) → 의사-erf로 근사 구현
- GroupConvolution → SeparableConvolution으로 대체
- argmax → reducemax로 우회
변환 도구 선택
변환 도구는 두 가지 옵션을 고려했습니다. 첫 번째는 Google 공식 도구인 ai-edge-torch로, PyTorch에서 LiteRT로 직접 변환할 수 있다는 장점이 있었지만 옵션이 부족하고 2024년 당시에는 정식 릴리스된 지 얼마 되지 않아서 불안정한 상태였으며 연산 대체가 제한적이었습니다.
또 다른 선택지는 ONNX2TF라는 서드파티 프로젝트였습니다. ONNX2TF는 PyTorch → ONNX → TensorFlow → LiteRT 경로로 복잡하게 변환되지만 연산 대체 옵션이 풍부하고 커뮤니티가 활발하며 변환 성공률이 높았습니다.
# ONNX2TF 변환 예시 onnx2tf -i model.onnx \ -o LiteRT_model \ -osd \ --replace_pseudo_erf \ --replace_group_conv_to_depthwise_conv결론적으로 변환 성공률이 높은 ONNX2TF를 사용하여 모델 변환을 수행했습니다.
양자화 옵션 비교 및 선택
모바일용으로 모델을 전환할 때 흔히 크기를 줄이기 위해 양자화를 도입합니다. 이를 위해 여러 양자화 옵션을 실험했습니다.
| PyTorch | FP32 | FP32 | 205.38MB | 93.2% | 15.97 it/s |
| LiteRT | FP16 | FP16 | 102.72MB | 93.21% | 15.97 it/s |
| LiteRT (최종) | FP16 | Dynamic | 62.76MB | 93.21% | 15.97 it/s |
| LiteRT | Dynamic | Dynamic | 52.43MB | 85.67% | 4.64 it/s |
최종적으로 이미지 인코더는 FP16, 텍스트 인코더는 동적 범위 양자화(dynamic range quantization)를 적용한 조합을 선택했습니다. 이를 통해 모델 크기를 70% 감소시켰고(205MB → 63MB), 정확도는 93.21%로 유지했으며, 속도도 15.97 it/s로 유지했습니다. 동적 범위 양자화를 텍스트 인코더에만 적용한 이유는 텍스트 인코더가 이미지보다 정밀도 손실에 덜 민감하기 때문입니다.
LiteRT 버전 정합성 고려
또 하나 고려해야 할 현실적인 제약은 LiteRT 버전 정합성입니다. Python 환경에서 변환에 사용한 TensorFlow 버전과 실제 모바일 앱에 탑재된 LiteRT 런타임 버전이 어긋나면 연산 지원 범위가 달라져 런타임 실패로 이어질 수 있습니다.
일반적으로 Android용 LiteRT 런타임의 버전 업데이트가 늦기 때문에(보통 1~2개 마이너 버전이 뒤처짐) 자칫 서로 버전이 맞지 않아 모델을 읽는 단계에서 실패하는 경우가 발생할 수 있습니다. 이때 Android의 Google Play Services에 내장된 LiteRT 런타임을 활용하면 배포가 편할 수는 있지만 이 경우 '기본 제공 연산'만 쓸 수 있어 선택 연산(selected ops) 사용이 제한될 수 있습니다. 따라서 모델 변환 단계에서부터 모바일에서 실제로 가능한 연산만 사용하도록 제약을 걸어두는 것이 안전했습니다.
온디바이스 구현 2: 전처리/후처리 및 벡터 DB
모바일에서 정상 작동하지 않거나 성능이 잘 나오지 않는 사례를 추적해 보면 상당수가 전처리 혹은 후처리에서 모델의 학습 환경과 불일치한 점이 발생한 것이 원인이었습니다. 이를 위해 전처리, 후처리 단계에 특히 신경을 쓸 필요가 있습니다. 핵심은 학습 환경과 동일하게 만드는 것입니다.
이미지 전처리 시 확인한 사항
Python 환경에서 이미지를 처리할 때는 보통 모델에서 기본으로 제공하는 전처리 파이프라인을 사용하지만, 모바일 환경에서는 보통 직접 구현해야 합니다. 아래는 임베딩 모델에서 사용하는 전처리 파이프라인입니다.
- 224×224 크기로 조정(resize)
- 중앙 크롭(center crop)
- 정규화(normalization): [0 - 255] → [0 - 1]
이 과정에서 주의해야 할 점을 살펴보겠습니다.
RGB 순서 확인
Android Bitmap은 이름과 같이 4바이트 크기의 메모리에 0xAARRGGBB 형식의 비트값으로 이미지를 저장합니다. 하지만 모델은 입력으로 RGB 순서로 만들어진 부동소수점(float) 행렬을 기대합니다. 이 때문에 모델이 입력으로 기대하는 RGB 순서를 정확히 맞춰서 변환해야 합니다.
아래는 Android의 Bitmap을 RGB 부동소수점 행렬로 변환하는 예제 코드입니다.
private fun loadBitmapToTensorBuffer(bitmap: Bitmap, buffer: TensorBuffer) { val w = bitmap.width val h = bitmap.height val bitmapIntArray = IntArray(w * h) bitmap.getPixels(bitmapIntArray, 0, w, 0, 0, w, h) val floatArray = FloatArray(w * h * 3) var index = 0 for (pixel in bitmapIntArray) { // Bitmap은 0xAARRGGBB 형식 // Bit shift로 R, G, B 추출 val r = ((pixel shr 16) and 0xFF) / 255.0f val g = ((pixel shr 8) and 0xFF) / 255.0f val b = (pixel and 0xFF) / 255.0f floatArray[index++] = r floatArray[index++] = g floatArray[index++] = b } buffer.loadArray(floatArray, intArrayOf(1, h, w, 3)) }크기 조정 방식 차이 확인
또 한 가지 흔한 함정은 크기 조정 방식입니다. Python 학습 환경의 이미지 형식인 PIL에서는 크기 조정 시 변환 방법이 bilinear이 기본인 경우가 많지만, Android의 Bitmap.createScaledBitmap 함수를 사용하면 nearest neighbor가 기본으로 사용됩니다. 이 경우 임베딩을 생성했을 때 각 차원의 값이 미묘하게 다를 수 있습니다. 따라서 모델마다 임베딩으로 변환했을 때 유사도에 유의미한 차이가 있는지 확인해 볼 필요가 있습니다. 만약 차이가 있다면 크기 조정 방식을 명시적으로 지정해 사용하는 방법도 있습니다.
후처리 L2 정규화 확인
코사인 유사도를 계산하기 위해서는 임베딩 정규화가 필수입니다. 저희는 다음과 같이 정규화했습니다.
fun normalize(embedding: FloatArray): FloatArray { val norm = sqrt(embedding.map { it * it }.sum()) return embedding.map { it / norm }.toFloatArray() }토큰화기(tokenizer) 구현
여기에 더해, 텍스트 입력을 임베딩으로 만들려면 일단 텍스트를 토큰화하기 위해 토큰화기를 사용해야 합니다. 이미지 전처리 때와 마찬가지로 모델에서 제공해 주는 것이 없기 때문에 토큰화기를 구현할 필요가 있습니다.
처음에는 원 모델의 토큰화기를 모바일에서 그대로 재현하려고 했지만 이 과정이 생각보다 난이도가 높았습니다. 다국어 문자를 처리해야 하고, 대소문자 처리와 일본어 가타카나/히라가나, 태국어 성조 기호, 중국어(번체) 같은 다국어 특수 문자를 처리해야 했습니다. 이 같은 정책이 임베딩 결과에 직접 영향을 주기 때문입니다.
이에 저희는 레퍼런스 구현을 기반으로 Kotlin 토큰화기를 만들었습니다. 이때 학습 때 사용한 토큰화기의 vocab/merges 파일과 1:1로 맞추는 것을 최우선했습니다.
// 핵심 토큰화기 로직 class CLIPTokenizer( private val bpeVocab: Map<String, Int>, private val maxLength: Int = 77 ) { fun tokenize(text: String, language: String): IntArray { // 1. 소문자 변환 (case insensitive) val normalized = text.lowercase() // 2. BPE 인코딩 val tokens = bpeEncode(normalized) // 3. 길이 조정 (패딩 또는 truncate) return padOrTruncate(tokens, maxLength) } private fun bpeEncode(text: String): List<Int> { // BPE 알고리즘 구현 // 자주 등장하는 문자 조합을 하나의 토큰으로 압축 ... } }추론 구현
추론 성능 관점에서는 ByteBuffer 할당과 복사를 무시하기 어렵습니다. 앱에서 흔히 쓰는 List<Float>나 Map<String, Any> 같은 구조를 그대로 LiteRT에 있는 모델에 넘길 수 없기 때문에 결국 FloatArray/IntArray → ByteBuffer → TensorBuffer로 변환하는 과정이 필요합니다. 특히 텍스트 토큰의 경우, 당시 LiteRT가 INT64를 직접 지원하지 않아(모바일 런타임/옵션에 따라 다름) 토큰 타입을 어떻게 표현할지 고민했습니다. 고민 끝에 저희는 UINT8 기반 ByteBuffer 8개를 엮어서 'INT64에 해당하는 레이아웃'을 맞추는 방식으로 우회했고, 이 과정에서 불필요한 메모리 복사가 최소화되도록 버퍼 재사용을 적용했습니다.
성능을 튜닝하기 위해 HNSW(hierarchical navigable small world)를 지원하는 벡터 DB 도입
벡터 DB 후보 선정 기준
이미지 검색을 온디바이스에서 하려면 사용자의 갤러리(혹은 캐시된 이미지)를 임베딩으로 만들어 저장해 두고, 쿼리가 들어올 때 빠르게 근접 이웃을 찾아야 합니다. 데이터가 커질수록 선형 탐색은 불가능해지고, 결국 ANN(approximate nearest neighbor) 인덱스가 필요합니다.
HNSW는 ANN 분야에서 널리 쓰이는 구조로, 검색 속도와 재현율(recall)의 균형을 잘 잡을 수 있다는 장점이 있습니다. 특히 온디바이스 환경에서는 '검색 지연의 상한'이 UX를 결정하기 때문에, 재현율을 조금 양보하더라도 안정적인 지연을 보장하는 쪽이 더 중요해지는 경우가 많습니다.
이를 지원하는 라이브러리/스토리지 후보는 꽤 많았지만 ‘실제로 Android/iOS에서 안정적으로 쓸 수 있는가'를 기준으로 보면 선택지가 급격히 줄어듭니다. 예를 들어 FAISS 계열의 모바일 포팅은 iOS 중심이고, USearch 같은 라이브러리는 핵심이 C 기반이라도 Android 빌드/배포가 간단하지 않았습니다. SQLite 확장인 sqlite-vec도 흥미롭지만, 아직 검색 성능과 운영에 대한 검증이 충분하지 않습니다. 따라서, 여러 상용 제품을 포함하여 앞서 언급한 안정적인 모바일 크로스 플랫폼 지원과 HNSW를 지원하는 선택지를 찾는 것이 중요했습니다. 이런 점을 고려해 내부적으로 적절한 벡터 DB를 선정해 도입했습니다.
핵심 튜닝: HNSW 하이퍼파라미터 탐색 설계
온디바이스에서 튜닝의 목표는 '재현율 최대화'가 아니라 '제품 UX를 해치지 않는 선에서 충분한 재현율 확보'였습니다.
이를 위해 필수 파라미터인 M과 ef_construction을 정할 필요가 있었습니다. M은 각 노드의 최대 연결(edge) 수를 뜻합니다. 값이 크면 데이터 간 연결이 촘촘해져서 검색 정확도가 올라가지만 그만큼 메모리를 많이 사용하고 인덱싱 시간이 길어집니다. ef_construction은 인덱스 생성 시 얼마나 많은 주변 노드를 탐색할지 결정하는 값으로 인덱스의 품질을 결정합니다.
저희는 다음과 같이 HNSW의 성능을 테스트해 보았습니다. 데이터 크기(3K/10K/30K)와 파라미터(neighbors_per_node, indexing_search_count)를 그리드로 탐색했고, 검색 지연과 재현율을 함께 보면서 파레토 최적점을 찾았습니다.
탐색 범위는 다음과 같은 형태였습니다. 참고로 수치는 예시가 아니라 실제로 탐색했던 스케일을 그대로 적었습니다.
- 이미지 수: 3K / 10K / 30K
- neighbors_per_node: 16 / 32 / 48 / 64 / 128
- indexing_search_count: 50 / 100 / 200 / 300 / 400 / 500
- 벡터 적재 배치: 1000장 단위로 DB 삽입
30K 이미지 기준으로는 M=128, ef_construction=100이 균형이 좋았습니다. 값을 키우면 재현율은 오르지만 메모리와 인덱싱/검색 시간이 늘어납니다. 결국 '저희 앱에서 허용 가능한 범위'를 먼저 정하고, 그 안에서 가능한 좋은 점을 고르는 게 중요했습니다.
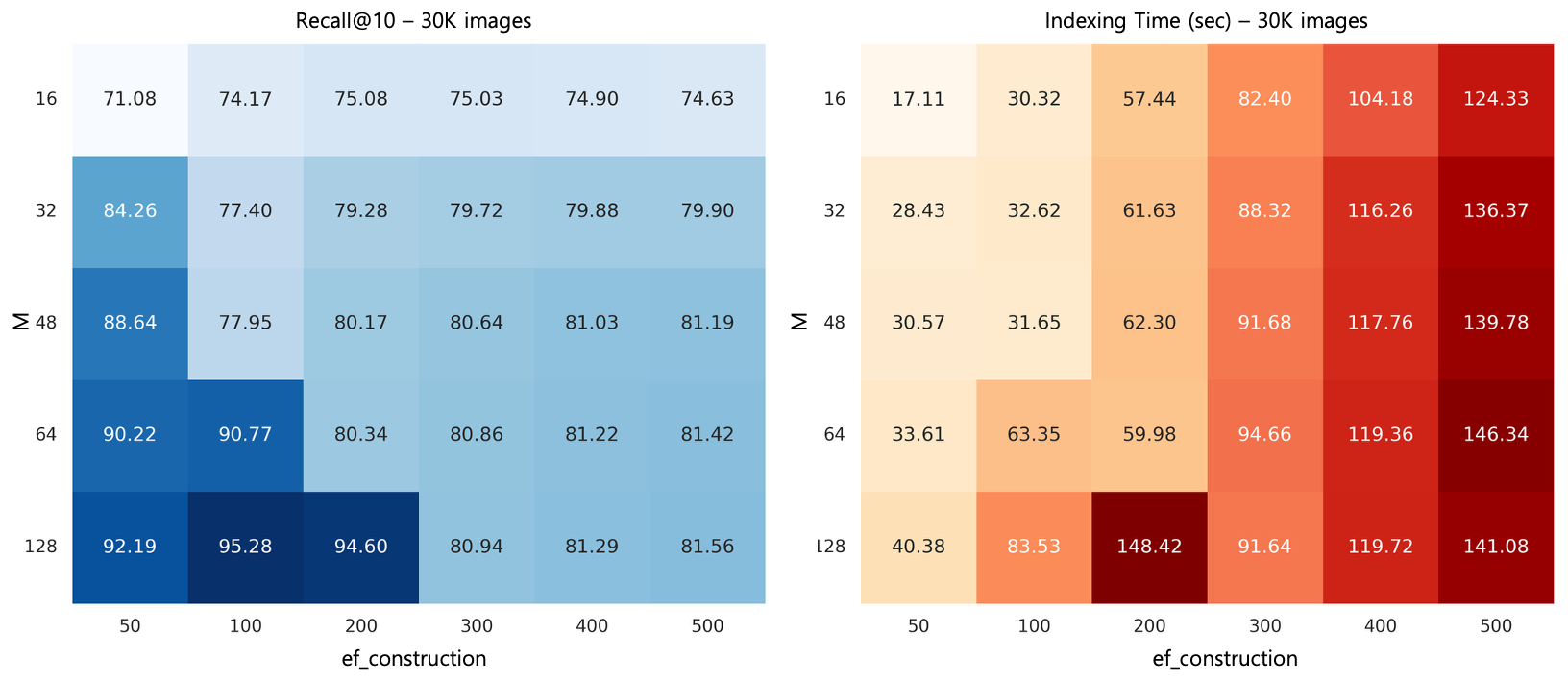 30K 이미지 실험 결과
30K 이미지 실험 결과
성능 측정 결과
실제 기기(Samsung Galaxy Fold 4, CPU)에서 성능 측정 결과
Samsung Galaxy Fold 4의 CPU 환경에서 측정한 인덱싱 성능은 이미지 인코딩과 DB 삽입을 합쳐 장당 250ms가 소요되었고, 10,000장을 인덱싱하는 데 백그라운드 처리로 약 40분이 걸렸습니다.
검색 성능은 텍스트 인코딩에 50~130ms(평균 100ms)가 소요되었고, HNSW를 사용한 DB 검색은 10,000장 기준으로 8~50ms(평균 10ms)가 걸려 총 지연 시간은 평균 약 110ms였습니다. 10,000장 기준에서도 속도가 크게 흔들리지 않는 점은 HNSW의 특성과 튜닝 효과가 결합된 결과라고 볼 수 있습니다.
도그푸딩 결과
도그푸딩을 통해 우선 다국어 검색이 잘 작동하는 것을 확인할 수 있었습니다. "강아지", "개", "멍멍이"가 모두 같은 이미지를 검색했고, "ラーメン", "ramen", "라면"도 동일한 결과를 반환했습니다.
또한 단순 키워드 검색이 아닌 의미론적 검색 결과도 볼 수 있었습니다. 아래 예제에서 볼 수 있듯 단순한 고양이 사진이 아니라, ‘상자 안의 고양이’, ‘새싹이 돋은 화분’과 같이 담긴 의미가 복잡한 사진이 1순위로 올라온 것을 볼 수 있었습니다. 실제 사용 과정에서 흥미로운 사례가 발견되기도 했습니다. 일례로 '컵에 그려진 고양이 얼굴'처럼 작은 영역만으로도 검색이 작동하거나, 특정 브랜드 로고도 예상치 못하게 인식하는 것을 발견할 수 있었습니다.
비디오 검색으로 확장
이미지 벡터 검색은 간단한 아이디어로 비디오 검색으로도 확장할 수 있었습니다. 아래와 같이 동영상 전체에서 10개 프레임을 전체 재생 시간에서 균등하게 샘플링하고, 각 프레임을 이미지 인코더로 인코딩한 뒤 평균 풀링(average pooling)으로 비디오 임베딩을 생성했습니다. 전략을 정리하면 다음과 같습니다.
- 균등 간격 프레임 샘플링(uniform frame sampling)(10 프레임)
- 각 프레임을 이미지 인코더로 인코딩
- 평균 풀링으로 비디오 임베딩 생성
비디오 검색 성능 측정 결과
다음은 성능 측정 결과입니다.
| CLIP4Clip | 150M | 42.1 | 71.9 | Fine-tuned |
| 자체 모델 | 53M | 31.6 | 56.3 | Zero-shot |
파라미터가 3배 적지만 비견할 만한 성능을 보였고, 파인 튜닝 없이 제로 샷으로 작동했으며, 추가 학습 없이 이미지 모델을 비디오로 확장할 수 있었다는 점에서 의의가 있습니다.
마치며
이번 1편에서는 번역 파이프라인의 한계를 출발점으로, 영어 임베딩 공간을 흔들지 않도록 이미지 인코더는 고정하고 텍스트 인코더만 지식 증류로 다국어 정렬해 Recall@5 기준으로 실사용 가능한 수준까지 끌어올린 과정을 정리했습니다. 또한 실제 배포 관점에서 PyTorch에서 LiteRT로 변환, 전처리/토큰화기 정합, 벡터 DB + HNSW 튜닝처럼 '모바일에서 실제로 돌아가게 만드는' 구현 포인트도 함께 다뤘습니다.
2편에서는 같은 온디바이스 조건에서 캡션 생성 시 병목이었던 자기회귀(AR) 디코딩(토큰당 지연 누적) 을 비자기회귀(non-AR) 병렬 생성으로 전환해 속도를 확보하고, 수락 비율 기반 평가와 데이터 재캡션(re-captioning), 지식 증류와 정제 반복으로 ‘속도는 빠르지만 품질이 떨어지는 문장이 생성되는 문제’를 어떻게 해결했는지 자세히 공유하겠습니다.
이 글은 2024년부터 2025년까지 약 6개월간 진행한 온디바이스 이미지 AI PoC 프로젝트의 기술적 경험을 공유하기 위해 작성했습니다. 실험 수치와 구현 세부사항은 내부 환경 및 기기 사양에 따라 달라질 수 있습니다.참고 자료
- 논문
- 지식 증류
- Radford et al., "Learning Transferable Visual Models From Natural Language Supervision", ICML 2021
- Wang et al., "Cross-lingual and Multilingual CLIP", LREC 2022
- Gou et al., "Knowledge Distillation: A Survey", arXiv 2021
- 벡터 검색
- Malkov and Yashunin, "Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs", TPAMI 2018
- 벤치마크
- Ramakrishna et al., "CIDEr: Consensus-based Image Description Evaluation", CVPR 2015
- Jack et al., "CLIPScore: A Reference-free Evaluation Metric for Image Captioning", EMNLP 2021
- 지식 증류
- 오픈소스
- 모델
- CLIP4Clip: https://github.com/ArrowLuo/CLIP4Clip
- 도구
- ONNX2TF: https://github.com/PINTO0309/onnx2tf
- ai-edge-torch: https://github.com/google-ai-edge/ai-edge-torch
- LiteRT: https://ai.google.dev/edge/litert
- FAISS Mobile: https://github.com/DeveloperMindset-com/faiss-mobile
- USearch: https://github.com/unum-cloud/USearch
- sqlite-vec: https://github.com/asg017/sqlite-vec
- 모델








 English (US) ·
English (US) · 